|
|
前言
c++图像算法CUDA加速
文章中一些概念目前理解不是很深,暂时当作笔记。
<hr/>1 内核(Kernels )
(1)Kernels (内核)
通过编写c++程序调用CUDA线程,这个c++调用函数称为内核(Kernels),内核在GPU线程中运行,在调用时,内核通过N个线程运行N次。
(2)Kernels的声明定义( __global__)
在c++程序中通过 __global__ 定义一个函数为内核。
(3)GPU线程设置与内核启动(<<<.....>>>)
通过 <<<.....>>> 设置调用CUDA的线程形状及数量并启动内核。(#include <cuda_runtime.h> )
(4)线程id
执行内核的每个CUDA线程都有唯一的线程id,该id可以通过内置变量( threadIdx)在内核函数中访问获得。(#include <device_launch_parameters.h>)
(5)示例1
// 定义内核函数,在设备的线程上运行
__global__ void VecAdd(float* A, float* B, float* C)
{
//获取线程id
int i = threadIdx.x;
C = A + B;
}
int main()
{
...
// 调用GPU N个线程,并启动内核
VecAdd << <1, N >> > (A, B, C);
...
}其中内核函数会被每个线程调用,即总共调用N次,每个线程计算对应的数组位置的加法。
<hr/>2 线程层次结构(Thread Hierarchy)
(1)线程的层次结构
线程(Thread )----线程块(Thread Block)----网格(Grid)
threadIdx:表示一个线程的索引。
blockIdx :表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim:表示单个线程块的大小。
gridDim :表示单个网格的大小,一个网格中通常有多个线程块。
(2)线程块(Thread Block)
线程块由线程组成,可以是一维,二维或者三维的,线程块中的线程id可以通过 threadIdx得到:
一维线程块:线程id = threadIdx.x;
二维线程块:线程id = threadIdx.x + threadIdx.y * blockDim.x;
三维线程块:线程id = threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
例2:三维线程块:
//定义内核
__global__ void MatAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
C = A + B;
}
int main()
{
...
// 创建一个三维线程块
int numBlocks = 1;
dim3 threadsPerBlock(N, N, N);
//启动内核
MatAdd << <numBlocks, threadsPerBlock >> > (A, B, C);
...
}备注:单个线程块中包含的线程是有限制的,目前单个线程块中线程的数量最大为1024。但是线程块的数量没有限制,因此总线程数位为 线程块的数量*每个块中的线程数。
(3)网格(Grid)
网格(Grid)由多个线程块组成,可以是一维,二维或者三维的,网格中线程块的id可以通过 blockIdx 得到。
例3:二维网格+二维线程块:
//定义内核
__global__ void MatAdd(float* A, float* B, float* C)
{
//当前线程块中的线程索引
int threadId_2D = threadIdx.x + threadIdx.y * blockDim.x;
//线程块的索引
int blockId_2D = blockIdx.x + blockIdx.y * gridDim.x;
//线程id = 线程块中线程索引 + 线程块索引 * 线程块中的线程数
int i = threadId_2D + (blockDim.x * blockDim.y) * blockId_2D;
C = A + B;
}
int main()
{
...
// 创建一个网格,包含二维的线程块,其中每个线程块中的线程也是二维的
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
//启动内核
MatAdd << <numBlocks, threadsPerBlock >> > (A, B, C);
...
}备注:一般设置单个线程块的线程数:16*16(256)
<hr/>3 内存层次结构(Memory Hierarchy)
(1)线程:每个线程都有自己的私有本地内存;
(2)线程块:每个线程库都有对块内所有线程可见的共享内存;
(3)线程块集群:线程块集群中的线程块都可以对彼此的共享内存执行读写和原子操作;
(4)全局内存(global):所有线程可以访问相同的全局内存;
(5)常量(constant)和纹理(texture)内存:两个额外的只读内存空间,所有线程可读。
<hr/>4 异构编程(Heterogeneous Programming )
异构:由主机和设备组成的系统
(1)CUDA的编程模型为:内核在设备线程中运行,其他c++程序在主机上运行,且主机和设备分别维护自己的内存(主机内存和设备内存)。主机程序管理对设备内核可见的全局、常量和纹理内存空间,包括设备内存的分配和释放,以及主机和设备之间的数据交互。
(2)统一内存:统一内存提供了托管内存来桥接主机和设备的内存空间。可以从系统中的所有cpu和gpu作为一个统一的一致性内存访问。此功能允许过度使用设备内存,并且通过消除在主机和设备上显式镜像数据的需要,可以大大简化移植应用程序的任务。
<hr/>5 异步SIMT编程模型(Asynchronous SIMT Programming Model)
(1)同步与异步:线程同步需要线程按顺序执行,所有线程都完成一件任务后才能继续下一个任务;线程异步只需要线程完成所有任务即可,不用管任务的执行顺序,不用等待其他线程。
(2)异步操作会使用同步对象来同步该操作的完成情况。这样的同步对象可以由用户显式地管理(cuda::memcpy_async),或在库中进行隐式管理(cooperative_groups::memcpy_async)。
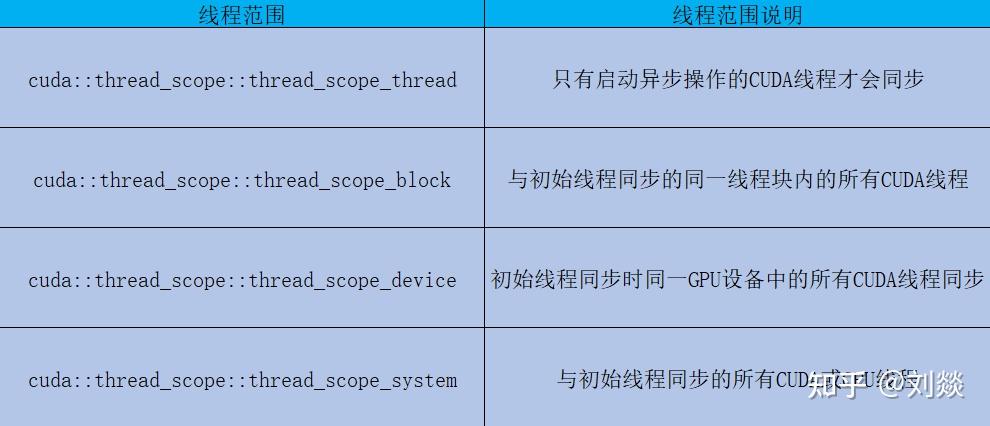
(3)同步对象: 栅栏(cuda::barrier) 或 管道( cuda::pipeline);这些同步对象可以在不同的线程范围中使用。作用域定义了可以使用同步对象与异步操作进行同步的线程集。下表定义了CUDA C++中可用的线程范围,以及可以与每个范围同步的线程。
<hr/>6 计算能力(Compute Capability)
(1)一个设备的计算能力用一个版本号表示,有时也被称为其“SM版本”。这个版本号标识了GPU硬件支持的特性,并在运行时被应用程序使用来确定哪些硬件特性和/或指令。
(2) 计算能力版本包括一个主要修订号X和一个次要修订号Y,用X.Y表示。具有相同主要修订号的设备具有相同的核心架构。
主要修订号与GPU架构:
9: NVIDIA Hopper GPU架构;
8: NVIDIA Ampere GPU 架构;
7:Volta架构;
6: Pascal 架构;
5:Maxwell 架构;
3:Kepler 架构。
次要修订号对应于对核心体系结构的增量改进,可能包括新特性。
GPU型号及对应的计算能力版本
备注:计算能力版本不是CUDA工具版本,从CUDA 7.0和CUDA 9.0开始,分别不再支持特斯拉和费米架构。
<hr/>7 数组相加示例
(1).cu文件
#include<iostream>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
/*核函数(设备运行函数)*/
__global__ void vectorAdd(const float* A, const float* B, float* C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x; //获取线程id
if (i < numElements)
{
C = A * B + 10;
}
}
/*主机函数*/
void test1(int num)
{
/*生成主机数据内存 h_A, h_B, h_C*/
int numElements = num;
size_t size = numElements * sizeof(float);
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
for (int i = 0; i < numElements; ++i)
{
h_A = rand() / (float)RAND_MAX;
h_B = rand() / (float)RAND_MAX;
}
/*生成设备内存 d_A,d_B,d_C */
float* d_A = NULL;
cudaMalloc((void**)&d_A, size);
float* d_B = NULL;
cudaMalloc((void**)&d_B, size);
float* d_C = NULL;
cudaMalloc((void**)&d_C, size);
/*将主机内存数据复制到设备内存 h_A--d_A,h_B--d_B */
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
/*设置设备的线程数,并调用核函数*/
int threadsPerBlock = 256; //每个线程块的线程数量
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock; //线程块的数量
vectorAdd <<< blocksPerGrid, threadsPerBlock >>> (d_A, d_B, d_C, numElements);
cudaGetLastError();
/*将设备内存数据复制到主机内存 d_C--h_C */
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
/* 释放设备内存 d_A d_B d_C */
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
/* 结果验证 */
std::cout << &#34;A[0]: &#34; << (float)h_A[0] << &#34; B[0]: &#34; << (float)h_B[0] << &#34; 结果C[0] = A + B + 10: &#34; << (float)h_C[0] << std::endl;
std::cout << &#34;A[1]: &#34; << (float)h_A[1] << &#34; B[1]: &#34; << (float)h_B[1] << &#34; 结果C[1] = A + B + 10: &#34; << (float)h_C[1] << std::endl;
std::cout << &#34;A[2]: &#34; << (float)h_A[2] << &#34; B[2]: &#34; << (float)h_B[2] << &#34; 结果C[2] = A + B + 10: &#34; << (float)h_C[2] << std::endl;
/* 释放主机内存 h_A h_B h_C */
free(h_A);
free(h_B);
free(h_C);
}(2).cpp文件
void test1(int num);
int main(void)
{
/*调用CUDA*/
test1(5000);
return 0;
} |
|



 发表于 2022-12-3 19:13:18
发表于 2022-12-3 19:13:18